

查询优化器在逻辑优化阶段主要解决的问题是:如何找出SQL语句等价的变换形式,使得SQL执行更高效。
用于优化的思路包括:

各种逻辑优化技术依据关系代数和启发式规则进行。
查询优化技术的理论基础是关系代数。
关系数据库基于关系代数。关系数据库的对外接口是SQL语句,所以SQL语句中的DML、DQL基于关系代数实现了关系的运算。
作为数据库查询语言的基础,关系模型由关系数据结构、关系操作集合和关系完整性约束三部分组成。与关系模型有关的概念:

关系代数的运算符类别包括:

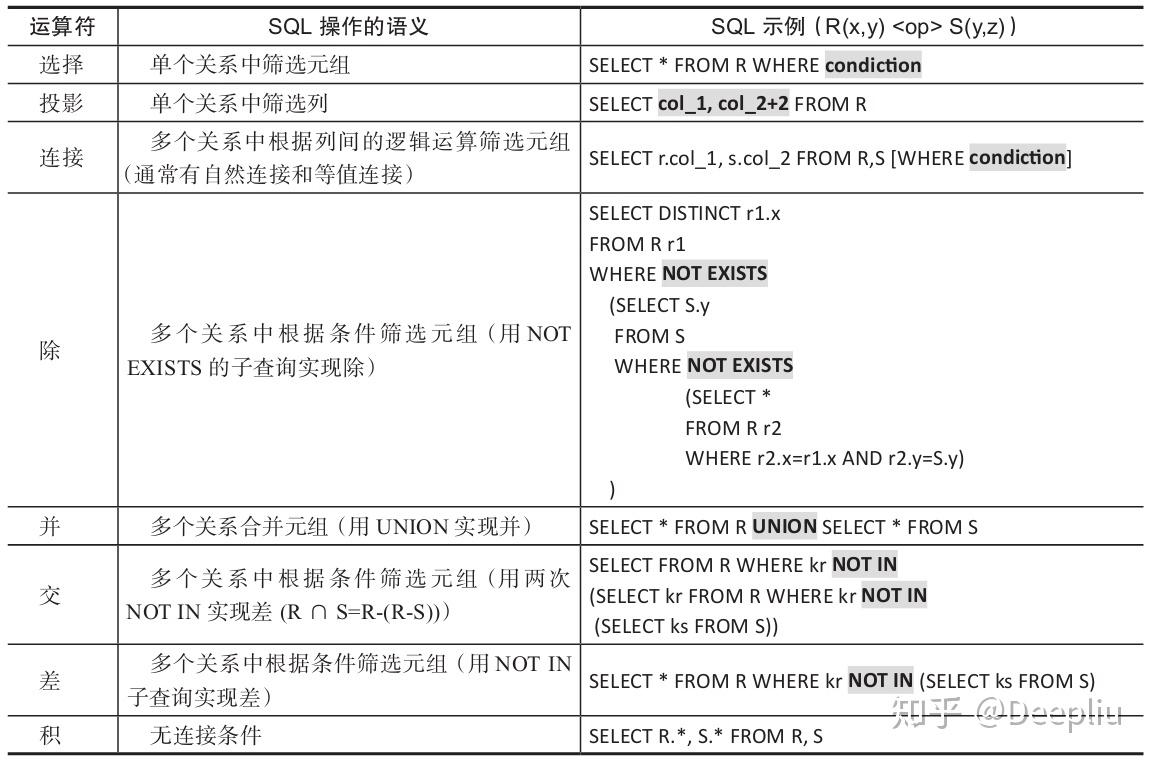
基本关系运算与对应的SQL表(表2-1):
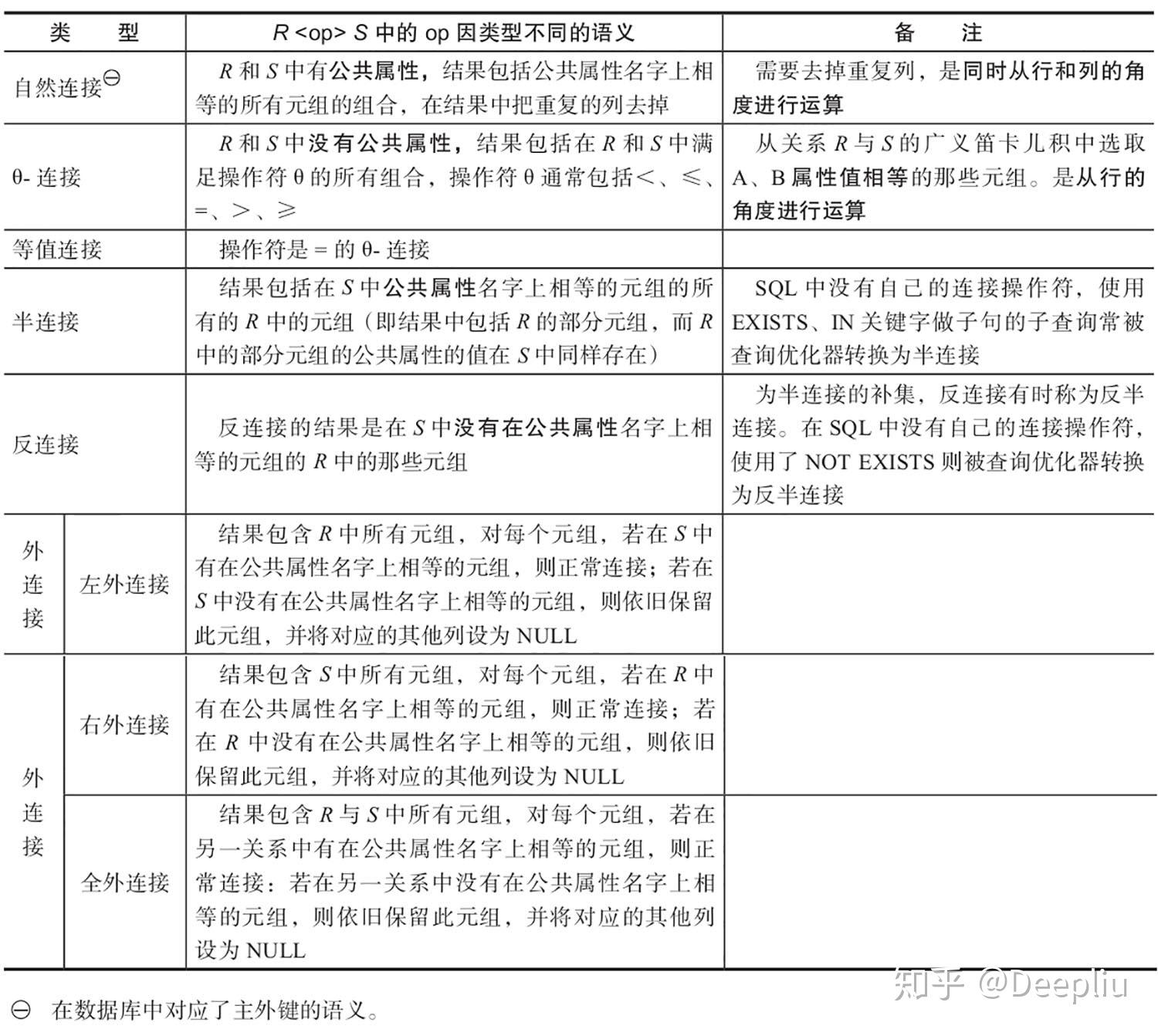
各种连接运算的语义表(表2-2):
关系代数表达式的等价,就是相同的关系代替两个表达式中相应的关系,所得到的结果是相同的。两个关系表达式El和E2是等价的,记为E1≡E2。
查询语句可以表示为一棵二叉树,其中:
- 叶子是关系。
- 内部结点是运算符(或称算子、操作符,如LEFTOUT JOIN),表示左右子树的运算方式。
- 子树是子表达式或SQL片段。
- 根结点是最后运算的操作符。
- 根结点运算之后,得到的是SQL查询优化后的结果。
- 这样一棵树就是一个查询的路径。
- 多个关系连接,连接顺序不同,可以得出多个类似的二叉树。
- 查询优化就是找出代价最小的二叉树,即最优的查询路径。每条路径的生成,包括了单表扫描、两表连接、多表连接顺序、多表连接搜索空间等技术。
- 基于代价估算的查询优化就是通过计算和比较,找出花费最少的最优二叉树。
最后两项,主要依据重写规则和物理查询优化中涉及的技术。
不同运算符根据其特点,可以对查询语句做不同的优化。但优化的前提是:优化前和优化后的语义必须等价。
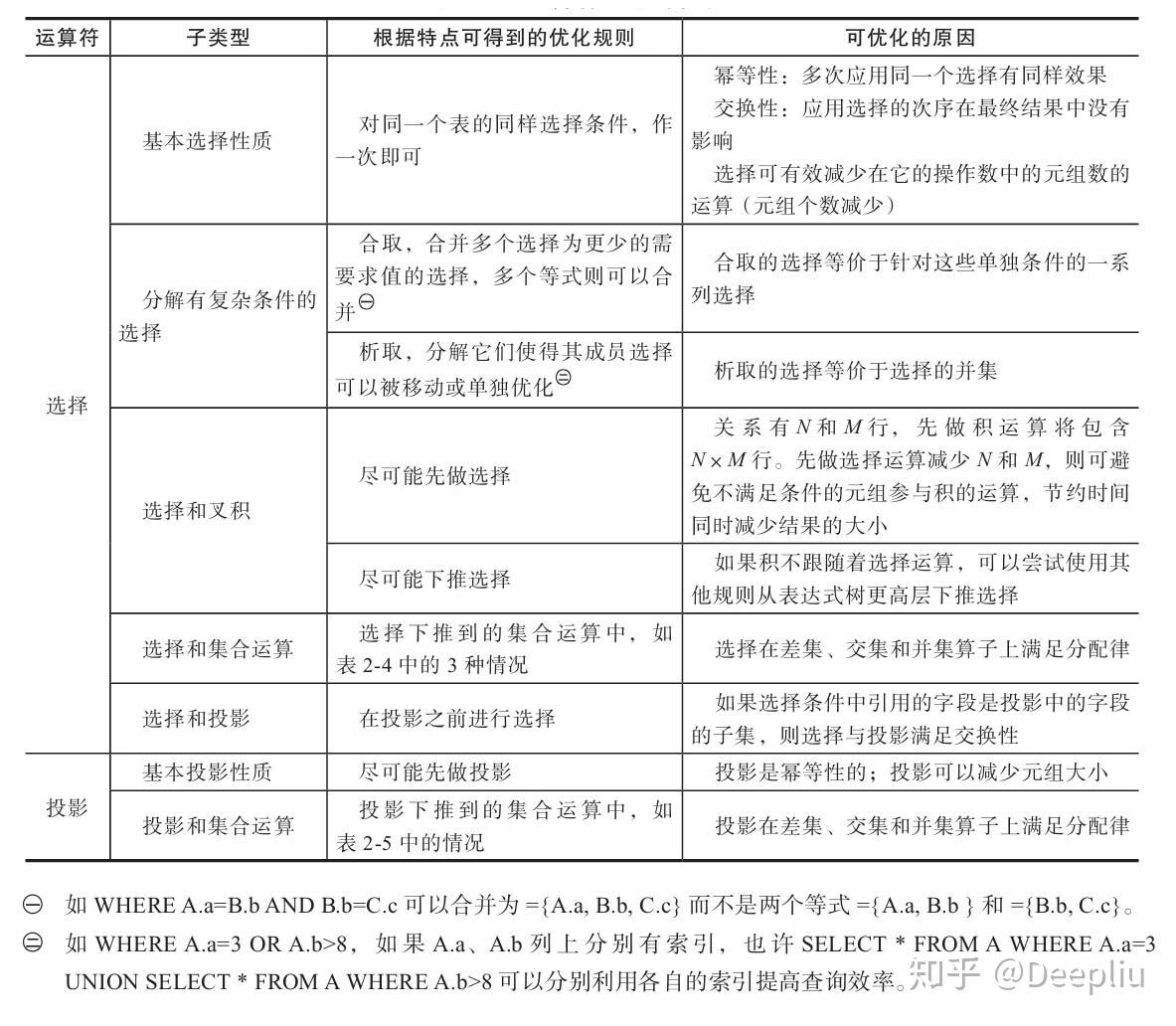
运算符主导的优化(表2-3):
选择下推到集合的运算(表2-4):

投影下推到集合的运算(表2-5):

经过等价变换优化带来的好处,再加上避免了原始方式引入的坏处,使得查询效率明显获得提升。
因为运算符中考虑的子类型(见表2-3中的“子类型”列),实则是部分考虑了运算符间的关系、运算符和操作数间的关系,其本质是运算规则在起作用。所以前节考虑过关系代数运算规则对优化的作用,但不完整,这里补充余下的对优化有作用的主要关系代数运算规则。
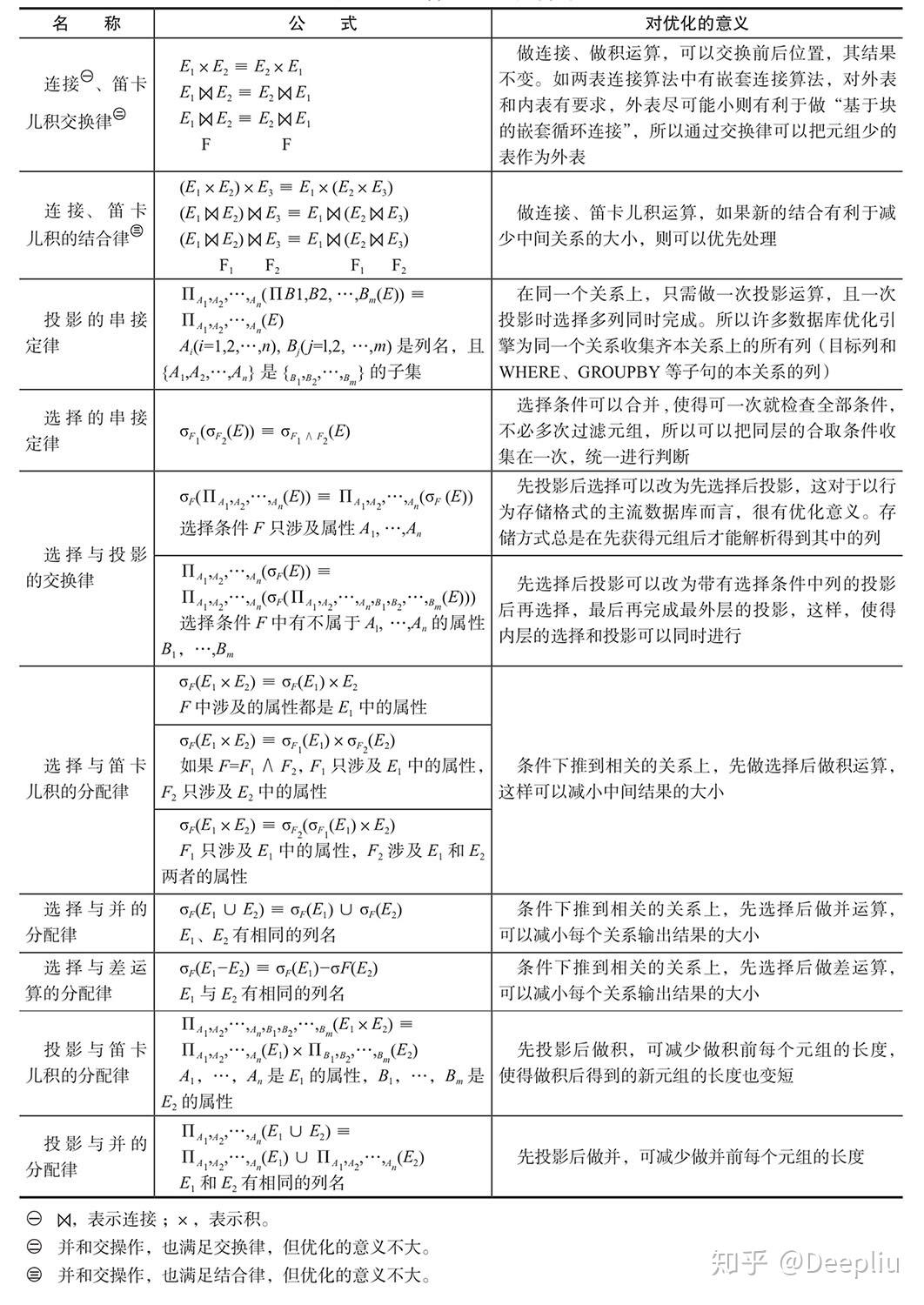
运算规则主导的优化(表2-6):
传统的联机事务处理(OLTP)使用基于选择(SELECT)、投影(PROJECT)、连接(JOIN)3种基本操作相结合的查询,称为SPJ查询。对这3种基本操作优化的方式如下:
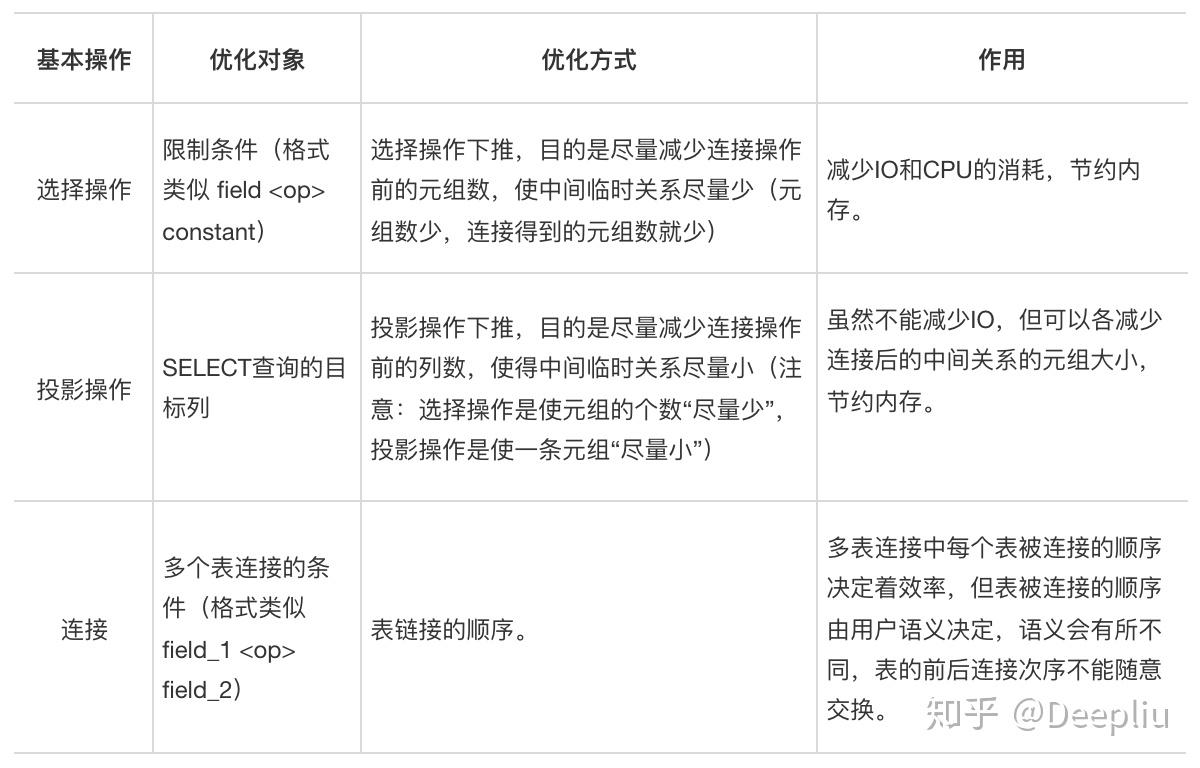
根据SQL语句的形式特点,还可以做如下区分:
- 针对SPJ的查询优化。基于选择、投影、连接3种基本操作相结合的查询。
- 针对非SPJ的查询优化。在SPJ的基础上存在GROUPBY操作的查询,这是一种较为复杂的查询。
针对SPJ和非SPJ的查询优化,其实是对以上多种操作的优化。“选择”和“投影”操作,可以在关系代数规则的指导下进行优化。表连接,需要多表连接的相关算法完成优化。其他操作的优化多是基于索引和代价估算完成的。
子查询在查询语句中经常出现,是比较耗时的操作。优化子查询对查询效率的提升有着直接的影响,所以子查询优化技术,是数据库查询优化引擎的重要研究内容。
子查询出现在SQL语句的位置和对优化的影响:
- 目标列。只能是标量子查询,否则数据库可能返回类似“错误:子查询必须只能返回一个字段”的提示。
- FROM子句。数据库可能返回类似“在FROM子句中的子查询无法参考相同查询级别中的关系”的提示,所以相关子查询不能出现在FROM子句中;非相关子查询出现在FROM子句中,可上拉子查询到父层,在多表连接时统一考虑连接代价后择优。
- WHERE子句。子查询是一个条件表达式的一部分,而表达式可以分解为操作符和操作数;根据参与运算的数据类型的不同,操作符也不尽相同,这对子查询均有一定的要求(如INT型的等值操作,要求子查询必须是标量子查询)。另外,子查询出现在WHERE子句中的格式也有用谓词指定的一些操作,如IN、BETWEEN、EXISTS等。
- JOIN/ON子句。可以拆分为两部分,一是JOIN块类似于FROM子句,二是ON子句块类似于WHERE子句,这两部分都可以出现子查询。子查询的处理方式同FROM子句和WHERE子句。
- GROUPBY子句。目标列必须和GROUPBY关联。可将子查询写在GROUPBY位置处,但子查询用在GROUPBY处没有实用意义。
- HAVING子句。
- ORDERBY子句。可将子查询写在ORDERBY位置处。但ORDERBY操作是作用在整条SQL语句上的,子查询用在ORDERBY处没有实用意义。
按子查询中的关系对象与外层关系对象间的关系分类:
- 相关子查询。子查询的执行依赖于外层父查询的一些属性值。当父查询的参数改变时,子查询需要根据新参数值重新执行,如:
SELECT * FROM t1 WHERE col_1 = ANY(SELECT col_1 FROM t2 WHERE t2.col_2 = t1.col_2); /*子查询语句中存在父查询的t1表的col_2列*/- 非相关子查询。子查询的执行不依赖于外层父查询的任何属性值,可独自求解,形成一个子查询计划先于外层的查询求解,如:
SELECT * FROM t1 WHERE col_1 = ANY(SELECT col_1 FROM t2 WHERE t2.col_2 = 10); /*子查询语句中(t2)不存在父查询(t1)的属性*/
按特定谓词分类:
- [NOT]IN/ALL/ANY/SOME子查询。语义相近,表示“[取反]存在/所有/任何/任何”,左面是操作数,右面是子查询,是最常见的子查询类型之一。
- [NOT]EXISTS子查询。半连接语义,表示“[取反]存在”,没有左操作数,右面是子查询,也是最常见的子查询类型之一。
- 其他子查询。除了上述两种外的所有子查询。
按语句的构成复杂程度分类:
- SPJ子查询。由选择、连接、投影操作组成的查询。
- GROUPBY子查询。SPJ子查询加上分组、聚集操作组成的查询。
- 其他子查询。GROUPBY子查询中加上其他子句如Top-N、LIMIT/OFFSET、集合、排序等操作。后两种子查询有时合称非SPJ子查询。
按结果集的角度分类:
- 标量子查询。子查询返回的结果集类型是一个单一值(return a scalar,a single value)。
- 列子查询。子查询返回的结果集类型是一条单一元组(return a single row)。
- 行子查询。子查询返回的结果集类型是一个单一列(return a single column)。
- 表子查询。子查询返回的结果集类型是一个表(多行多列)(return a table,one or more rows ofone or more columns)。
(1)做子查询优化的原因
在数据库实现早期,查询优化器对子查询一般采用嵌套执行的方式,即对父查询中的每一行,都执行一次子查询,这样子查询会执行很多次,效率很低。
对子查询进行优化,可能带来几个数量级的查询效率的提高。子查询转变成为连接操作之后,有如下好处:
- 子查询不用执行很多次。
- 优化器可以根据统计信息来选择不同的连接方法和不同的连接顺序。
- 子查询中的连接条件、过滤条件分别变成了父查询的连接条件、过滤条件,优化器可以对这些条件进行下推,以提高执行效率。
(2)子查询优化技术
子查询优化技术的思路如下:
- 子查询合并(Subquery Coalescing)。在某些条件下,多个子查询能够合并成一个子查询。如:
SELECT * FROM t1 WHERE a1<10 AND (EXISTS (SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=1) OR EXISTS (SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=2));
-- 可优化为:
SELECT * FROM t1 WHERE a1<10 AND (EXISTS (SELECT a2 FROM t2 WHERE t2.a2<5 AND (t2.b2=1 OR t2.b2=2) /*大两个EXISTS子句合并为一个,条件也进行了合并*/- 子查询展开(Subquery Unnesting)。又称子查询反嵌套或子查询上拉。把一些子查询置于外层的父查询中,作为连接关系与外层父查询并列,其实质是把某些子查询重写为等价的多表连接操作。有关的访问路径、连接方法和连接顺序可能被有效使用,使得查询语句的层次尽可能地减少。常见的IN/ANY/SOME/ALL/EXISTS依据情况转换为半连接(SEMI JOIN)、普通类型的子查询消除等情况属于此类,如:
SELECT * FROM t1, (SELECT * FROM t2 WHERE t2.a2>10) v_t2 WHERE t1.a1<10 AND v_t2.a2<20;
--可优化为:
SELECT * FROM t1, t2 WHERE t1.a1<10 AND t2.a2<20 AND t2.a2> 10;/*子查询变为了t1、t2表的连接操作,相当于把t2表从子查询中上拉了一层*/- 聚集子查询消除(Aggregate SubqueryElimination)。聚集函数上推,将子查询转变为一个新的不包含聚集函数的子查询,并与父查询的部分或者全部表做左外连接。通常,一些系统支持的是标量聚集子查询消除,如:
SELECT * FROM t1 WHERE t1.a1 > (SELECT avg(t2.a2) FROM t2);- 其他。利用窗口函数消除子查询的技术(Remove Subquery using Window functions,RSW)、子查询推进(Push Subquery)等技术可用于子查询的优化。
(3)子查询展开
子查询展开是一种最为常用的子查询优化技术,子查询展开有以下两种形式:
- 如果子查询中出现了聚集、GROUPBY、DISTINCT子句,则子查询只能单独求解,不可以上拉到上层。
- 如果子查询只是一个简单格式(SPJ格式)的查询语句,则可以上拉到上层,往往能提高查询效率。子查询上拉讨论的就是这种格式,也是子查询展开技术处理的范围。
把子查询上拉到上层,前提是上拉(展开)后的结果不能带来多余的元组,所以需要遵循如下规则:
- 如果上层查询的结果没有重复(即SELECT子句中包含主码),则可以展开其子查询,并且展开后查询的SELECT子句前应加上DISTINCT标志。
- 如果上层查询的SELECT语句中有DISTINCT标志,则可以直接进行子查询展开。
- 如果内层查询结果没有重复元组,则可以展开。
子查询展开的具体步骤如下:
1)将子查询和上层查询的FROM子句连接为同一个FROM子句,并且修改相应的运行参数。
2)将子查询的谓词符号进行相应修改(如:IN修改为=ANY)。
3)将子查询的WHERE条件作为一个整体与上层查询的WHERE条件合并,并用AND条件连接词连接,从而保证新生成的谓词与原谓词的上下文意思相同,且成为一个整体。
子查询的格式有多种,常见的子查询格式有IN类型、ALL/ANY/SOME类型、EXISTS类型。
(1)IN类型
IN类型有3种不同的格式:
-- 格式一:
outer_expr [NOT] IN (SELECT inner_expr FROM ...WHERE subquery_where)
-- 格式二:
outer_expr = ANY (SELECT inner_expr FROM ... WHERE subquery_where)
--- 格式三:
(oe_1,oe_N) [NOT] IN (SELECT ie_1, ie_N FROM ... WHERE subquery_where)IN类型子查询优化的情况表(表2-7):

情况一:outer_expr和inner_expr均为非NULL值。
优化后的表达式(外部条件outer_expr下推到子查询中):
EXISTS (SELECT 1 FROM ... WHERE subquery.where AND outer_expr=inner_expr)
-- 即:
EXISTS (SELECT 1 FROM ... WHERE subquery_where AND oe_1 = ie_1 AND ... AND oe_N = ie_N)子查询优化需要全部满足两个条件:
- outer_expr和inner_expr不能为NULL。
- 不需要从结果为FALSE的子查询中区分NULL。
情况二:outer_expr是非NULL值(情况一的两个转换条件中至少有一个不满足时)。
优化后的表达式(外部条件outer_expr下推到子查询中,另外内部条件inner_expr为NULL):
EXISTS (SELECT 1 FROM ... WHERE subquery.where AND (outer_expr = inner_expr OR inner_expr IS NULL))假设outer_expr是非NULL值,但是如果outer_expr=inner_expr表达式不产生数据,则outer_expr IN (SELECT ...)的计算结果有如下情况:
- 为NULL值。SELECT语句查询得到任意的行数据,inner_expr是NULL(outer_expr IN (SELECT ...)==NULL)。
- 为FALSE值。SELECT语句产生非NULL值或不产生数据(outer_expr IN (SELECT ...)==FALSE)。
情况三:outer_expr为NULL值。
原先的表达式等价于:
NULL IN (SELECT inner.expr FROM ... WHERE subquery_where)假设outer_expr是NULL值,NULL IN(SELECTinner_expr...)的计算结果有如下情况:
- 为NULL值。SELECT语句产生任意行数据。
- 为FALSE值。SELECT语句不产生数据。
还有需要说明的是:
- 谓词IN等价于=ANY。
- 带有谓词IN的子查询,如果满足上述3种情况,可以做等价变换。
(2)ALL/ANY/SOME类型
ALL/ANY/SOME类型的子查询格式:
outer_expr operator ANY (subquery) outer_expr operator SOME (subquery) outer_expr operator ALL (subquery)使用这类子查询需要注意:
- operator为操作符,通常可以是<、=<、>、>=中的任何一个。具体是否支持某个操作符,取决于表达式值的类型。
- =ANY与IN含义相同,可以采用IN子查询优化方法。
- SOME与ANY含义相同。
- NOT IN与<>ALL含义相同。
- NOT IN与<>ANY含义不相同。
- <> ANY表示不等于任何值。
如果子查询中没有GROUPBY子句和聚集函数,则下面的表达式还可以使用聚集函数MAX/MIN做类似下面的等价转换:
- val>ALL(SELECT...)等价变化为val>MAX(SELECT...)
- val<ALL(SELECT...)等价变化为val<MIN(SELECT...)
- val>ANY(SELECT...)等价变化为val>MIN(SELECT...)
- val<ANY(SELECT...)等价变化为val<MAX(SELECT...)
- val>=ALL(SELECT...)等价变化为val>=MAX(SELECT...)
- val<=ALL(SELECT...)等价变化为val<=MIN(SELECT...)
- val>=ANY(SELECT...)等价变化为val>=MIN(SELECT...)
- val<=ANY(SELECT...)等价变化为val<=MAX(SELECT...)
(3)EXISTS类型
EXISTS类型的子查询格式:
[NOT] EXISTS (subquery)需要注意几点:
- EXISTS对于子查询而言,其结果值是布尔值;如果subquery有返回值,则整个EXISTS(subquery)的值为TRUE,否则为FALSE。
- EXISTS(subquery)不关心subquery返回的内容,这使得带有EXISTS(subquery)的子查询存在优化的可能。
- EXISTS(subquery)自身有着“半连接”的语义,所以,一些数据库实现代码中(如PostgreSQL),用半连接完成EXISTS(subquery)求值。
- NOT EXISTS(subquery)通常会被标识为“反半连接”处理。
- 一些诸如IN(subquery)的子查询可以等价转换为EXISTS(subquery)格式,所以可以看到IN(subquery)的子查询可被优化为半连接实现的表连接。
视图重写就是将对视图的引用重写为对基本表的引用。视图重写后的SQL多被作为子查询进行进一步优化。所有的视图都可以被子查询替换,但不是所有的子查询都可以用视图替换。
从视图的构成形式可以分为:
- 简单视图,用SPJ格式构造的视图。
- 复杂视图,用非SPJ格式构造(带有GROUPBY等操作)的视图。
示例:
-- 创建表和视图
CREATE TABLE t_a(a INT, b INT);
CREATE VIEW v_a AS SELECT * FROM t_a;
-- 视图的查询命令
SELECT col_a FROM v_a WHERE col_b>100;
-- 视图重写后的形式
SELECT col_a FROM (
SELECT col_a, col_b FROM t_a
) WHERE col_b > 100;
-- 优化后的等价形式:
SELECT col_a FROM t_a WHERE col_b > 100;
简单视图能被较好地优化;但是复杂视图则不能被很好的优化器。像Oracle等商业数据库,提供了一些视图的优化技术,如“复杂视图合并”、“物化视图查询重写”等。但复杂视图优化技术还有待提高。
数据库执行引擎对一些谓词处理的效率要高些,因此把逻辑表达式重写成等价的且效率更高的形式,能有效提高查询执行效率。这就是等价谓词重写。
1. LIKE规则
改写LIKE谓词为其他等价的谓词,以更好地利用索引进行优化。如:
name LIKE 'Abc%'
-- 重写为
name >= 'Abc' AND name < 'Abd'应用LIKE规则的好处是:转换前只能进行全表扫描,如果目标列上存在索引,则转换后可以进行索引范围扫描。
LIKE匹配的表达式中,若没有通配符(%或_),则与=等价。如:
name LIKE 'Abc'
-- 重写为
name = 'Abc'
2. BETWEEN-AND规则
改写BETWEEN-AND谓词为其他等价的谓词,以更好地利用索引进行优化。与LIKE谓词的等价重写类似,如:
sno BETWEEN 10 AND 20
-- 重写为
sno >= 10 AND sno <= 20应用BETWEEN-AND规则的好处是:如果sno上建立了索引,则可以用索引扫描代替原来BETWEEN-AND谓词限定的全表扫描,从而提高了查询的效率。
http://3.IN转换OR规则
这里是指IN操作符操作,不是IN子查询。改写IN谓词为等价的OR谓词,以更好地利用索引进行优化。如:
age IN (8,12,21)
-- 重写为
age = 8 OR age = 12 OR age = 21如果数据库对IN谓词只支持全表扫描且OR谓词中表的age列上存在索引,则转换后查询效率会提高。
http://4.IN转换ANY规则
改写IN谓词为等价的ANY谓词。因为IN可以转换为OR,OR可以转为ANY,所以可以直接把IN转换为ANY。如
age IN (8,12,21)
-- 重写为
age ANY (8,12,21)效率是否能够提高,依赖于数据库对于ANY操作的支持情况。如PostgreSQL没有显式支持ANY操作,但是在内部实现时把IN操作转换为了ANY操作。
5.OR转换ANY规则
改写OR谓词为等价的ANY谓词,以更好地利用MIN/MAX操作进行优化。如:
sal>1000 OR dno=3 AND (sal>1100 OR sal>base_sal+100) OR sal>base_sal+200 OR sal>base_sal*2
-- 重写为
dno=3 AND (sal >1100 OR sal>base_sal+100) OR sal >ANY (1000, base_sal+200, base_sal*2)OR转换ANY规则依赖于数据库对于ANY操作的支持情况。PostgreSQL V9.2.3和MySQLV5.6.10目前都不支持本条规则。
6.ALL/ANY转换集函数规则
将ALL/ANY谓词改写为等价的聚集函数MIN/MAX谓词操作,以更好地利用MIN/MAX操作进行优化。如:
sno > ANY (10, 2*5+3, sqrt(9))
-- 重写为
sno > sqrt(9)通常,聚集函数MAX()、MIN()等的执行效率比ANY、ALL谓词的执行效率高。如果有索引存在,求解MAX/MIN的效率更高。
7.NOT规则
NOT谓词的等价重写。如下:
NOT (col_1 != 2) 重写为 col_1 = 2
NOT (col_1 != col_2) 重写为 col_1 = col_2
NOT (col_1 = col_2) 重写为 col_1 != col_2
NOT (col_1 < col_2) 重写为 col_1 >= col_2
NOT (col_1 > col_2) 重写为 col_1 <= col_2如果在col_1上建立了索引,则可以用索引扫描代替原来的全表扫描,从而提高查询的效率。
8.OR重写并集规则
OR条件重写为并集操作,形如以下SQL示例:
SELECT * FROM student WHERE (sex='f' AND sno>15) OR age>18;假设所有条件表达式的列上都有索引(即sex列和age列上都存在索引),为了能利用索引处理上面的查询,可以将语句改成如下形式:
SELECT * FROM student WHERE sex='f' and sno>15 UNION SELECT * FROM student WHERE age>18;改写后的形式,可以分别利用列sex和age上的索引,进行索引扫描,然后再提供执行UNION操作获得最终结果。
WHERE、HAVING和ON条件由许多表达式组成,利用等式和不等式的性质,可以将它们的条件化简,但不同数据库的实现可能不完全相同。不同数据库的实现可能不同。
条件化简的方式如下:
- 把HAVING条件并入WHERE条件。便于统一、集中化解条件子句,节约多次化解时间。仅在SQL语句中不存在GROUPBY条件或聚集函数的情况下,才能进行合并。
- 去除表达式中冗余的括号。减少语法分析时产生的AND和OR树的层次。如((a AND b) AND (c AND d))就可以化简为a AND b AND c AND d。
- 常量传递。对不同关系可以使得条件分离后有效实施“选择下推”,从而可以极大地减小中间关系的规模。如col_1=col_2 AND col_2=3就可以化简为col_1=3 AND col_2=3。操作符=、<、>、<=、>=、<>、LIKE中的任何一个,在col_1 <操作符> col_2条件中都会发生常量传递。
- 消除死码。去除不必要的条件。如WHERE (0>1 AND s1=5),0>1使得AND恒为假,则WHERE条件恒为假。去除可以加快查询执行的速度。
- 表达式计算。对可以求解的表达式进行计算。如WHERE col_1=1+2变换为WHERE col_1=3。
- 等式变换。改变某些表的访问路径,如反转关系操作符的操作数的顺序。如-a=3可化简为a=-3。如果a上有索引,则可以利用索引扫描加快访问。
- 不等式变换。去除不必要的重复条件。如a>10 AND b=6 AND a>2可化简为b=6 AND a>10。
- 布尔表达式变换。布尔表达式还有如下规则指导化简。
- 谓词传递闭包。如<、>等比较操作符具有传递性,可以化简表达式。如由a>b AND b>2可以推导出a>b AND b>2 AND a>2,a>2是一个隐含条件,这样把a>2和b>2分别下推到对应的关系上,就可以减少参与比较操作a>b的元组了。
- 任何一个布尔表达式都能被转换为一个等价的合取范式(CNF)。因为合取项只要有一个为假,整个表达式就为假,故代码中可以在发现一个合取项为假时,即停止其他合取项的判断,以加快判断速度。另外因为AND操作符是可交换的,所以优化器可以按照先易后难的顺序计算表达式。
- 索引的利用。如果一个合取项上存在索引,则先判断索引是否可用,如能利用索引快速得出合取项的值,则能加快判断速度。同理,OR表达式中的子项也可以利用索引。
1. 外连接消除的意义
外连接的左右子树不能互换,并且外连接与其他连接交换连接顺序时,必须满足严格的条件以进行等价变换。
查询重写的一项技术就是把外连接转换为内连接,对优化的意义如下:
- 查询优化器在处理外连接操作时所需执行的操作和时间多于内连接。
- 优化器在选择表连接顺序时,可以有更多更灵活的选择,从而可以选择更好的表连接顺序,加快查询执行的速度。
- 表的一些连接算法(如块嵌套连接和索引循环连接等)将规模小的或筛选条件最严格的表作为“外表”(放在连接顺序的最前面,是多层循环体的外循环层),可以减少不必要的IO开销,极大地加快算法执行的速度。
PostgreSQL外连接注释表(表2-8):
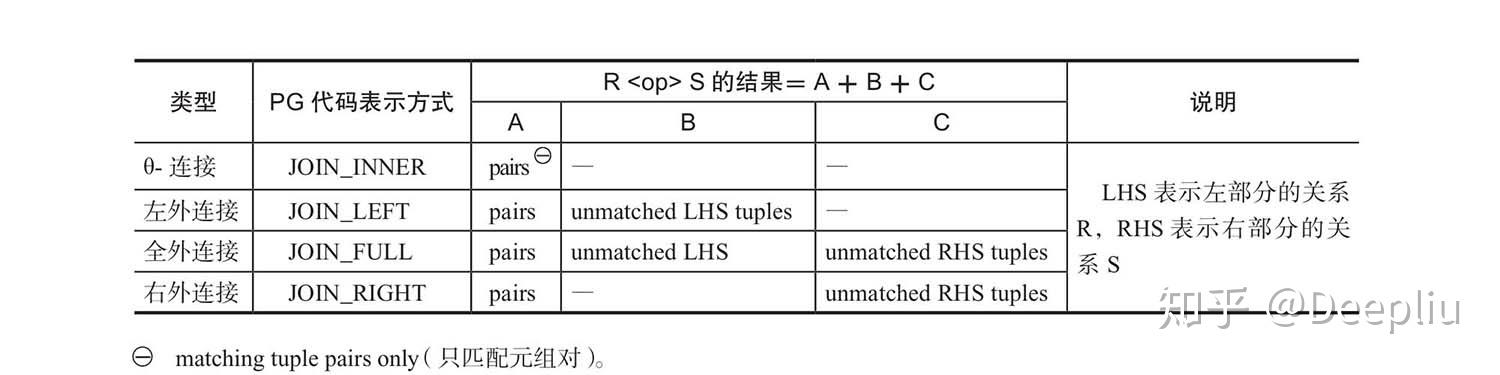
分3种情况讨论表2-8,来弄明白,为什么外连接可以转换为内连接?(有点复杂,后续根据需要再详细了解)
2. 外连接消除的条件
外连接可转换为内连接的条件:WHERE子句中与内表相关的条件满足“空值拒绝”(reject-NULL条件)。一般认为下面任意一种情况满足空值拒绝:
- 条件可以保证从结果中排除外连接右侧(右表)生成的值为NULL的行,所以能使该查询在语义上等效于内连接。
- 外连接的提供空值的一侧为另一侧的每行只返回一行。如果该条件为真,则不存在提供空值的行,并且外连接等价于内连接。
当执行连接操作的次序不是从左到右逐个进行时,就说明这样的连接表达式存在嵌套。如:
SELECT * FROM t1 LEFT JOIN (t2 LEFT JOIN t3 ON t2.b=t3.b) ON t1.a=t2.a WHERE t1.a>1另外一种格式用括号把连接次序做了区分:
SELECT * FROM A JOIN (B JOIN C ON B.b1=C.c1) ON A.a1=B.b1 WHERE A.a1 > 1;
-- 可以等价转换为
SELECT * FROM A JOIN B JOIN C ON B.b1=C.c1 ON A.a1=B.b1 WHERE A.a1 > 1;综上可得以下结论:
- 如果连接表达式只包括内连接,括号可以去掉,这意味着表之间的次序可以交换,这是关系代数中连接的交换律的应用。
- 如果连接表达式包括外连接,括号不可以去掉,意味着表之间的次序只能按照原语义进行,至多能执行的就是外连接向内连接转换的优化。
连接的分类:

其中外链接的优化前面讨论过,下面分情况讨论其它可优化的连接。
情况一:主外键关系的表进行的连接,可消除主键表,这不会影响对外键表的查询。
如:
CREATE TABLE B (b1 INT, b2 VARCHAR(9), PRIMARY KEY(b1));
CREATE TABLE A (a1 INT, a2 VARCHAR(9), FOREIGN KEY(a1) REFERENCES B(b1));
CREATE TABLE C (c1 INT, c2 VARCHAR(9));
情况二:唯一键作为连接条件,三表内连接可以去掉中间表(中间表的列只作为连接条件)。
如:
CREATE TABLE A (a1 INT UNIQUE, a2 VARCHAR(9),a3 INT);
CREATE TABLE B (b1 INT UNIQUE, b2 VARCHAR(9),c2 INT);
CREATE TABLE C (c1 INT UNIQUE, c2 VARCHAR(9),c3 INT);B的列在WHERE条件子句中只作为等值连接条件存在,则查询可以去掉对B的连接操作。
SELECT A.*, C.* FROM A JOIN B ON (a1=b1) JOIN C ON (b1=c1);
-- 相当于
SELECT A.*, C.* FROM A JOIN C ON (a1= c1);
情况三:其他一些特殊形式
如:
SELECT MAX(a1) FROM A, B;/* 在这样格式中的MIN、MAX函数操作可以消除连接,去掉B表不影响结果,其他聚集函数不可以*/
SELECT DISTINCT a3 FROM A, B; /* 对连接结果中的a3列执行去重操作*/
SELECT a1 FROM A, B GROUP BY a1;/* 对连接结果中的a1列执行分组操作*/语义优化包括以下基本概念:
- 语义转换,因为完整性限制等原因使得一个转换成立的情况。
- 语义优化,因为语义转换形成的优化。
语义转换是根据完整性约束等信息对“某特定语义”进行推理,得到一种查询效率不同但结果相同的查询。
语义优化是从语义的角度对SQL进行优化,不是一种形式上的优化,所以其优化的范围可能覆盖其他类型的优化范围。
语义优化常见的方式如下:
- 连接消除(Join Elimination)。对一些连接操作先不必评估代价,根据已知信息(主要依据完整性约束等)能推知结果或得到一个简化的操作。如“视图重写"中的例子。
- 连接引入(Join Introduction)。增加连接有助于原关系变小或原关系的选择率降低。
- 谓词引入(Predicate Introduction)。根据完整性约束等信息引入新谓词,如引入基于索引的列,可能使得查询更快。如一个表上,有c1<c2的列约束,c2列上存在一个索引,查询语句中的WHERE条件有c1>200,则可以推知c2>200,WHERE条件变更为c2>200 AND c1>200 AND c1<c2,由此可以利用c2列上的索引,对查询语句进行优化。如果c2列上的索引的选择率很低,则优化效果会更高。
- 检测空回答集(Detecting the Empty AnswerSet)。查询语句中的谓词与约束相悖,可以推知条件结果为FALSE,也许最终的结果集能为空;如CHECK约束限定score列的范围是60到100,而一个查询条件是score<60,则能立刻推知条件不成立。
- 排序优化(Order Optimizer)。ORDERBY操作通常由索引或排序(sort)完成;如果能够利用索引,则排序操作可省略。另外,结合分组等操作,考虑ORDERBY操作的优化。
- 唯一性使用(Exploiting Uniqueness)。利用唯一性、索引等特点,检查是否存在不必要的DISTINCT操作,如在主键上执行DISTINCT操作,若有则可以把DISTINCT消除掉。
非SPJ查询,查询中包含GROUPBY子句。
1. GROUPBY优化
可考虑分组转换技术,即对分组操作、聚集操作与连接操作的位置进行交换。常见方式如下:
- 分组操作下移。GROUPBY操作可能较大幅度地减少关系元组的个数,如果能够对某个关系先进行分组操作,然后再进行表之间的连接,很可能提高连接效率。这种优化方式是把分组操作提前执行。下移的含义,是在查询树上让分组操作尽量靠近叶子结点,使得分组操作的结点低于一些选择操作。
- 分组操作上移。如果连接操作能够过滤掉大部分元组,则先进行连接后,再进行GROUPBY操作,可能提高分组操作的效率。这种优化方式是把分组操作置后执行。上移的含义和下移正好相反。
另外,GROUPBY、ORDERBY优化的另外一个思路是尽量利用索引。
2. ORDERBY优化
对于ORDERBY的优化,可有如下方面的考虑:
- 排序消除(Order By Elimination,OBYE)。优化器在生成执行计划前,将语句中没有必要的排序操作消除(如利用索引)。
- 排序下推(Sort push down)。把排序操作尽量下推到基表中,有序的基表进行连接后的结果符合排序的语义,这样能避免在最终的大的连接结果集上执行排序操作。
3. DISTICT优化
可考虑如下方面:
- DISTINCT消除(Distinct Elimination)。如果表中存在主键、唯一约束、索引等,则可以消除查询语句中的DISTINCT(这种优化方式本质上是语义优化研究的范畴)。
- DISTINCT推入(Distinct Push Down)。生成含DISTINCT的反半连接查询执行计划时,先进行反半连接再进行DISTICT操作,也许先执行DISTICT操作再执行反半连接更优,这是利用连接语义上确保唯一功能特性进行DISTINCT的优化。
- DISTINCT迁移(Distinct Placement)。对连接操作的结果执行DISTINCT,可能把DISTINCT移到一个子查询中优先进行(有的书籍称之为“DISTINCT配置”)。
逻辑优化阶段使用的启发式规则通常包括如下两类。
1. 一定能带来优化效果的,主要包括:
- 优先做选择和投影(连接条件在查询树上下推)。
- 子查询的消除。
- 嵌套连接的消除。
- 外连接的消除。
- 连接的消除。
- 使用等价谓词重写对条件化简。
- 语义优化。
- 剪掉冗余操作(一些剪枝优化技术)、最小化查询块。
2. 变换未必会带来性能的提高,需根据代价选择
- 分组的合并。
- 借用索引优化分组、排序、DISTINCT等操作。
- 对视图的查询变为基于表的查询。
- 连接条件的下推。
- 分组的下推。
- 连接提取公共表达式。
- 谓词的上拉。
- 用连接取代集合操作。
- 用UNIONALL取代OR操作。
- 《数据库查询优化的艺术:原理解析和SQL性能优化》,李海翔

