

单表优化是sql优化中最基础的部分,单表可以理解为复杂查询中的单表部分, 熟悉单表优化,应用于实际的sql优化中,解决sql效率低的问题。
一、基础知识
?
1、操作符
?执行计划中的每一个节点,每一个节点都是一个循环获取数据的过程。
单表优化中常见有NSET,PRJT2,CSCN2,SSEK,CSEK,SSCN等
?
?2、hint
客户端将sql语句提交给服务器后,优化器根据自己的算法,基于统计信息 生成一条认为代价最低的执行计划,但是有时计算出来的执行计划并不是最优的,我们可以根据实际情况,给优化器提示,让优化器根据提示修正执行计划。
3、提前返回
执行一条语句的时候,当得出的结果 满足FIRST_ROWS 设置的值时,语句就停止执行,可以向客户端发出执行完成,返回数据。其实这个时间语句并没真正执行完成,这就叫做提前返回数据。在一些场景下 并不是要全部的数据,提前返回能尽快返回数据,提高体验感。
4、查询的基本结构
select id,mc from TAB where id<9999 order by id desc;
这条查询语句 select 后 为查询项,from 后为查询的表,where 后为条件列 ,order by 为排序或者分组模块。
二、单表优化
1、等值查询
等值查询为最基础的查询
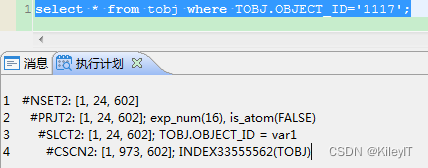
上图无索引的时候 是全表扫描,下图新建条件列索引后走了索引扫描
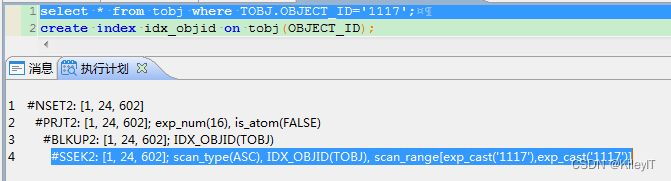
但是也需要注意:
条件的列过滤性是否比较好的,如果过滤性较差,查出的结果比较大还需要回表可能会比全表扫描更差。
传的值是否能转换成列的类型
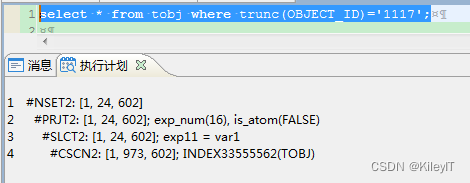
条件列套函数的时候,FUNC(OBJECT_ID)=xxx的时候,内部函数 可以 考虑做函数索引,但也有可能用的自定义函数,自定义函数为确定性函数才可。
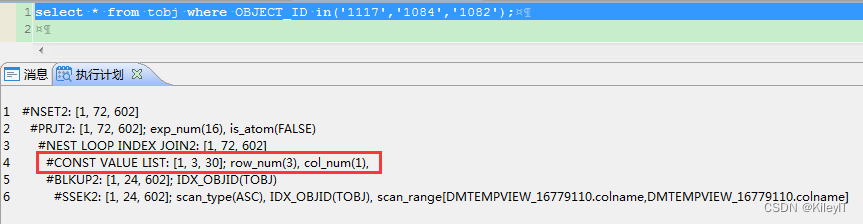
2、IN条件查询
In条件的查询 可以理解为多个等值条件,有两种处理
1.in的值作为参数表,将传入的3值分别和表连接。列有索引并且过滤性好的话 走的nest loop,否则将会走hash join
? 2.将in 作为一个整体条件处理。 IN 里面如果参数非常多,解析会非常耗时,影响性能。
3、范围条件
在条件列增加索引可达到优化效果,当然也要注意其过滤性。
范围的条件 会根据统计信息估算 大概返回多少行来选定 SSEK2 或者SSCN 的扫描方式。
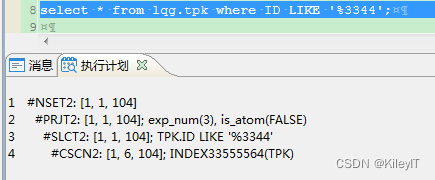
4、like条件
1.传值接%号的时候,如like fff||”%” 优化器会自动转换为 大于 fff 并且小于xxx 这样的查询方式。
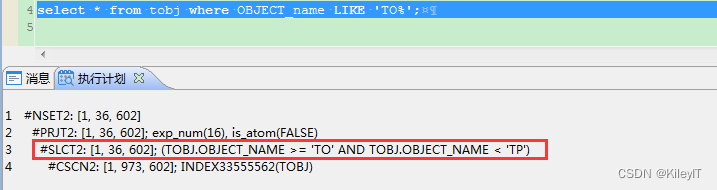
2.百分号加传值的时候,如lik ‘%’||fff ,这种情况下,可以通过两次反转 变成传值在前 而走函数索引。如 字段内容? AAAAAfff 是符合like ‘%’||fff的。通过函数 reverse 将字段的值反转过来为fffAAAAA, like 条件也反转like fff||”%” 最终like的 结果为一致的, 因此百分号加传值的时候,可以用reverse(c1) 并建立函数索引,把like反转来优化。
但是需要注意的是 reverse函数不忽略末尾空格,但是like 是考虑空格的。
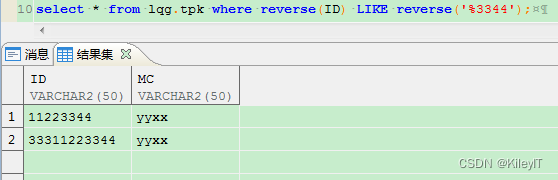
ID? MC
11223344 yyxx
33311223344 yyxx
dsr3344? ? yyxx
?通过反转函数下面这图 查询出来少了一行,因为 dsr3344 后面有空格。
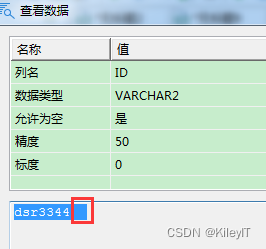
创建了 reverse(ID) 索引后,改写%在后面,成了 索引扫描

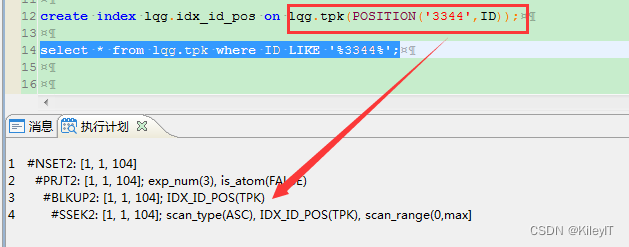
3. 前后% 号的 like 如? like ‘%3344%’ ,一般前后%号的like 无法优化的,但是3344为固定值的话可以转换成 POSITION函数,存在POSITION(‘3344’,ID)索引 就会走索引定位
如果 like’%中文%’ 可以考虑全文索引。
5、排序
最简单的 排序 字段 加所以 即可消除排序。排序的操作符为 SORT 。有排序的弊端为不能 提前返回数据了, 必须要扫描完成 排序后才可以返回。 排序列有索引的情况 直接扫描索引,满足行数后即可返回数据。
正常情况下的查询 是where 条件等于 后加某个字段排序, 这时可以加组合索引, 先定位where 条件的列,组合排序的列。
Id > 1000 order by mc? 这种情况下 要考虑条件过滤的多少数据,如果过滤后还有80% 大量数据的话可以考试 在mc 上建立索引,返回有序数据后再select.
如果返回数据量少 可以 建立 ID 和mc 的组合索引。
6、分组、分析函数
分组和排序类似,分组列在有索引的情况下,可以 通过扫描索引减少计算。
分析函数是按照OVER 后的PARTION 和ORDER 进行数据输出,对于同一个分组内的数据进行排序列排序
这个时候我们需要 PARTION BY 列 + ORDER 列的组合索引
7、多条件组合
都是等值的情况下,可以建立组合索引,要考虑过滤性。
有等值和范围的时候, 考虑过滤性后 建立等值索引在前 范围索引后的组合索引,范围索引只能用一个。
都是范围的情况, 只能取一个过滤性好的建立索引。
建立索引 考虑过滤性,定位少量数据后 可以slct 选择数据。
8、多条件组合 OR
HINT OPTIMIZER_OR_NBEXP 通过该hint 优化。 0 为分开,2为合并处理。
Where 的条件前面为公共部分, or 的是分支,当公共部分很复杂的时候,可以考虑公共部分作为一个临时表, OR_CVT_HTAB_FLAG 0表示公共部分不转换为临时表,1表示转换 。USE_HTAB_FLAG? 表示是否开启临时表功能,为0表示强制不使用
Or 非常多的情况,优化器more 处理7个分支,MAX_OPT_N_OR_BEXPS 可以调大处理的分支
9、层次查询
connect by col1 = prior.col2? start with col4 = v4 where col3 = v3;
的时候,v3 是不能提前处理的, 此时建立col1 索引,每次connect by都能快速定位。
from (select * from t1 where col3 = v3) connect by col1 = prior.col2 start with col4 = v4
Where col3 = v3; 这样查询一个子集的时候,v3会被优先处理,可以加上col3和col1 的组合索引。
对于CONNECT BY 子集比较多且无法建立索引或者过滤不佳的情况下,可以考虑将CNNTB_OPT_FLAG
HINT 成1,通过HASH 的方式进行层次查询操作
三、常用监控
1、ET的方法
会记录下各个操作符的执行次数及执行时间, 尽可能的只开启会话级参数
CALL SF_SET_SESSION_PARA_VALUE(’MONITOR_SQL_EXEC’,1);
CALL SF_SET_SESSION_PARA_VALUE(‘MONITOR_TIME’,1);
开启后 ET(执行号) 获取执行情况。
2、AUTOTRACE
这个是disql 的功能,开启的命令在DISQL中执行set autotrace trace,然后再执行语句,在开启MONITOR_SQL_EXEC的情况下,处理记录下各个操作符的执行
信息,还会记录下相关的行数信息,对比评估和实际返回的行数,差距大的部分可能执行计划有问题。
3、PLNDUMP
用来dump 真正的执行计划,判断内存的执行计划和 看到的是否有差别。
select cache_item,sqlstr from v$cachepln where sqlstr like ‘%where%’;
查询确认CACHE_ITEM号后 dump内存里的执行计划
Alter session set events? ’immediate trace name plndump,level 214587956’;
即可获得该计划的详细信息,存放在数据文件目录的trace文件夹下

